
Sponsored By: Masterworks
Masterworks is the award-winning platform helping 550,000+ invest in shares of multi-million dollar art by iconic names like Picasso, Basquiat, and Banksy.
Over the last few months, I’ve been obsessed with AI—chatting with AI researchers in London, talking product development with startups in Argentina, debating philosophy with AI safety groups in San Francisco. Among these diverse individuals, there is universal agreement that we are in a period of heightened excitement but almost total disagreement on how that excitement should be interpreted. Yes, this time is different for AI versus previous cycles—but what form that difference takes is hotly debated.
My own research on that topic has led me to propose two distinct strategy frameworks:
- Just as the internet pushed distribution costs to zero, AI will push creation costs toward zero.
- The economic value from AI will not be distributed linearly along the value chain but will instead be subject to rapid consolidation and power law outcomes among infrastructure players and end-point applications.
I still hold these frameworks to be true—now I’d like to apply them to six “micro-theories'' on how AI will play out.
This research matters more than typical startup theory. AI, if it fully realizes its promise, will remake human society. Existing social power dynamics will be altered. What we consider work, what we consider play—even the nature of the soul and what it means to be human—will need to be rethought. There is no technology quite like this. When I discuss the seedling AI startups of today, we are really debating the future of humanity. It is worthy of serious study.
1. Fine-tuned models win battles, foundational models win wars
My consolidation theory posited that the value chain for the AI market looked something like this:

I’ve since heard tales of multiple startups that had spent the last few years fine-tuning their own model for their own use case. Thousands of hours devoted to training, to labeling specific data sets, to curation. Then, when OpenAI released GPT-3, it was an order of magnitude better than their own version.
Fine-tuning makes requests much cheaper for narrow use cases. In the long term, it's not necessarily about fine-tuning beating foundational model performance but more like being deployed for narrow use cases to lower the cost of prompt completion. However, this can only happen when companies decide to train their own models. At a certain level of scale, it’s faster and easier to rely on someone else.
You can think of the AI model race as something like the graphic I made below. Fine-tune models can gradually improve over time, while foundational models appear to take step-changes up.
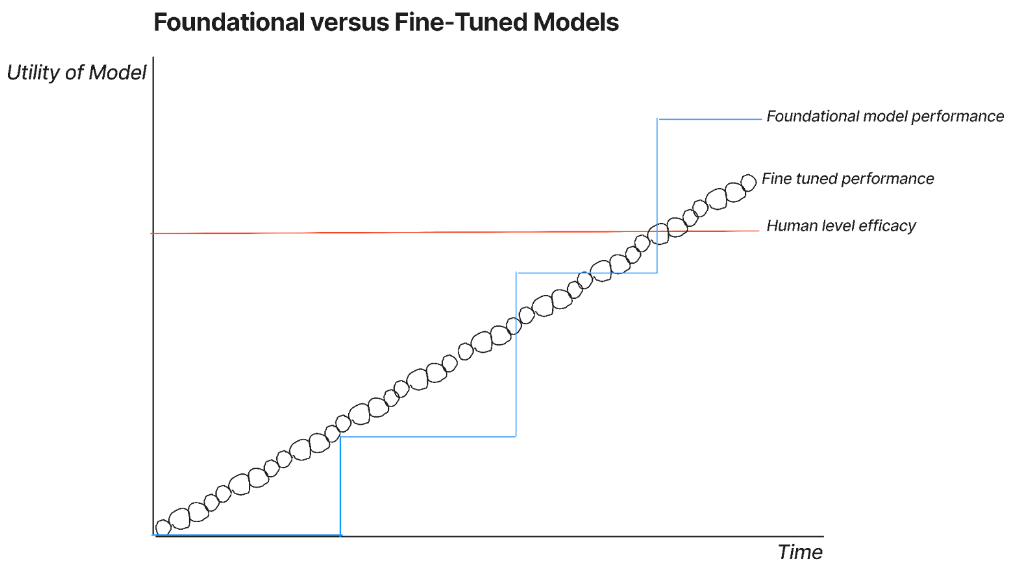
This graphic shows both strategies converging at the same point, but depending on your beliefs, you could have one outperforming another.
If this is the race, the natural question is: who will be the winner?
2. Long-term model differentiation comes from data-generating use cases
The current AI research paradigm is defined by scale. Victory is a question of more—more computing power, more data sets, more users. The large research labs will have all of that and over time will do better.
However, there is one instance where the graph will look like this:
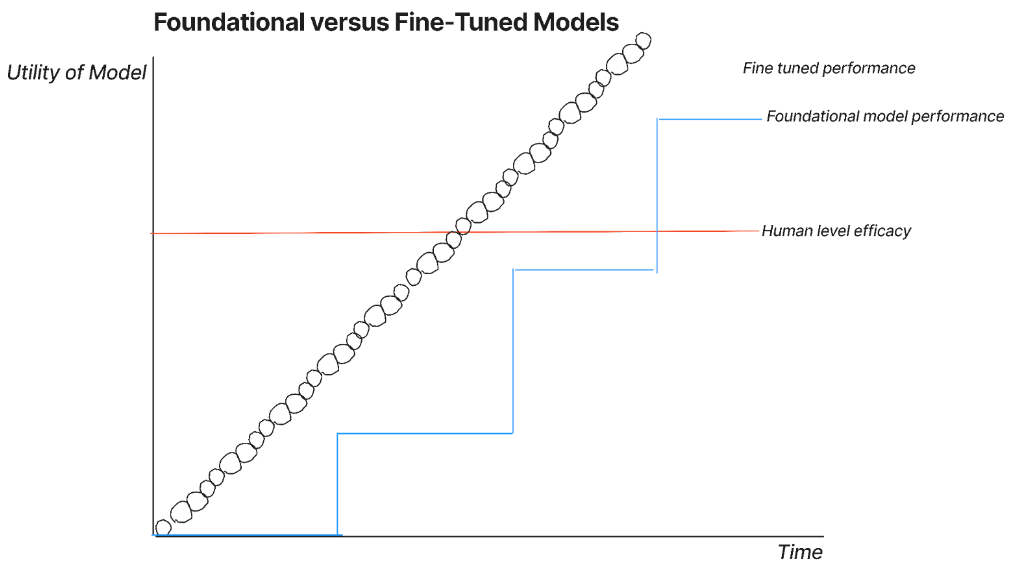
I drew the fine-tuned performance as a series of little circles, which represent data loops. Data loops occur when an AI provider is able to build feedback mechanisms into the product itself and then use that feedback to retrain the model. Sometimes they’ll do so by utilizing their own foundational model, sometimes they’ll fine-tune someone else’s model for their own use case. I think that this will require a model provider to also own the endpoint solution, but I’m open to being wrong on this point. Think of it as power-ranked 3) small, specialized model 2) large general model, and 3) large specialized model. The issue with stack rank 3 is that these can only exist if you make them yourselves. Startups that can capture that model to output to retrain model loop will be able to build a specialized winner.
3. Open source makes AI startups into consulting shops, not SaaS companies
For many years, most people assumed that AI would be a highly centralized technology. Foundational models would require so much data and computing power that only a select few could afford it. But that didn’t happen. Transformers, the math driving a lot of this innovation, didn’t require labeled data as previously thought. Look at what’s happened with image generation.
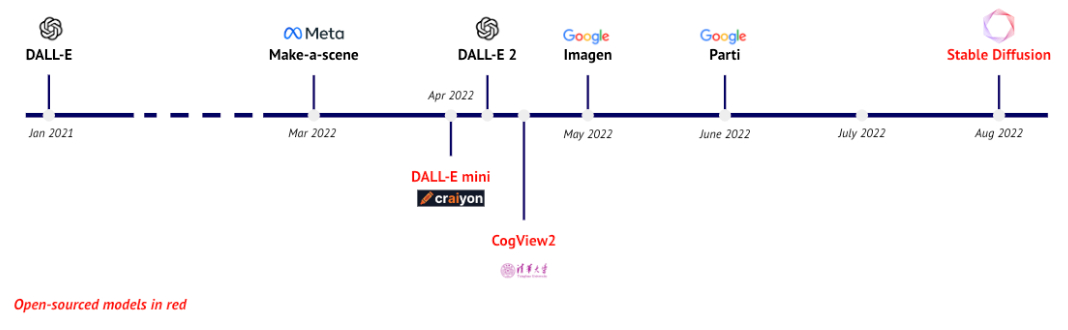
Source: State of AI Deck, 2022.
An even greater Cambrian explosion has happened in text generation.
The Only Subscription
You Need to
Stay at the
Edge of AI
The essential toolkit for those shaping the future
"This might be the best value you
can get from an AI subscription."
- Jay S.
Join 100,000+ leaders, builders, and innovators

Email address
Already have an account? Sign in
What is included in a subscription?
Daily insights from AI pioneers + early access to powerful AI tools



 Front-row access to the future of AI
Front-row access to the future of AI
 Bundle of AI software
Bundle of AI software

 Evan Armstrong
Evan Armstrong


 Dan Shipper
Dan Shipper
Comments
Don't have an account? Sign up!