
Sponsored By: Reflect
This article is brought to you by Reflect, a beautifully designed note-taking app that helps you to keep track of everything, from meeting notes to Kindle highlights.
Update: if you want to use the chat bot mentioned in this article, it's available for Every subscribers here:
In the future, any time you look up information you’re going to use a chatbot. This applies to every piece of information you interact with day to day: personal, organizational, and cultural.
On the personal side, if you're trying to remember an idea from a book you read, or something a colleague said in a meeting, or a restaurant a friend recommended to you, you’re not going to dig through your second brain. Instead, you’re going to ask a chatbot that sits on top of all of your notes, and the chatbot will return the right answer to you.
On the organizational side, if you have a question about a new initiative at your company, you’re not going to consult the internal wiki or bother a colleague. You’re going to ask the internal chatbot, and it will return an up-to-date, trustworthy answer to you in seconds.
On the cultural side, if you want to know what your favorite podcaster says about a specific topic, you’re not going to have to Google them, sort through an episode list, and listen to a two-hour audio file to find the answer. Instead, you’ll just ask a chatbot trained on their content library, and get an answer instantly.
This future may seem far out, but it’s actually achievable right now. I know, because I just built a demo over the weekend. And it already works.
. . .
I love listening to the Huberman Lab podcast, a neuroscience podcast by Stanford neurobiologist Andrew Huberman. It’s got a good mix of interesting science and actionable advice to improve how your brain and body operate.
Unfortunately, the episodes are also very long—each one averages a few hours. I often have a specific question related to something that he's already covered, but it's a pain to go back and try to find the answer by scrubbing through old episodes.
So I made a solution over the weekend: a Huberman Lab chatbot using GPT-3.

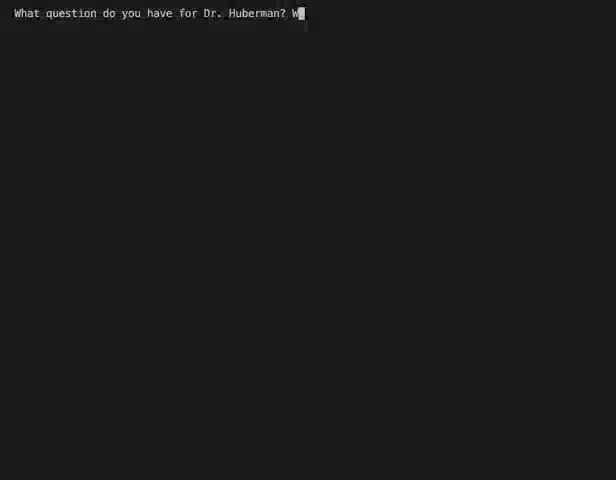

It was simple to build, and it can already answer questions plausibly well. I can ask questions about topics that the podcast has covered in the past, and it answers them using transcripts of old episodes as an information source.
Here’s a quick example. Dr. Huberman recently did an episode on the science of creating and maintaining habits. One of his suggestions is to do “task bracketing” to help create habits—a phrase I’ve had in my head to try since I listened to the episode, but I can’t remember exactly what it means.
Usually, I’d have to go and re-listen to the episode to answer the question. But instead I asked Huberman bot:
Me: Can you describe how to do task bracketing?
Huberman bot: Task bracketing involves dividing the 24-hour day into three phases: phase one (0 to 8 hours after waking up), phase two (8 to 16 hours after waking up), and phase three (16 to 24 hours after waking up). Place particular habits at particular phases of the day in order to engage the task-bracketing mechanisms. This will make it more likely that you will be able to regularly engage in these habits and activities over a long period of time. Additionally, positively anticipate the onset and the offset of the session and reward yourself for the entire experience. This will help shift your nervous system toward being able to predict that certain things are going to happen at particular times of day.
Me: Why do I divide the day into three phases when I'm doing task bracketing?
Huberman bot: Dividing the day into three phases when doing task bracketing is useful because it allows you to leverage neural systems in order to help you make it more likely that you're going to be able to engage and maintain a particular habit. Phase one (0-8 hours after waking) is useful for acquiring certain habits, phase two (9-14/15 hours after waking) is useful for acquiring other types of habits, and phase three (16-24 hours after waking) is useful for calming activities.
The Only Subscription
You Need to
Stay at the
Edge of AI
The essential toolkit for those shaping the future
"This might be the best value you
can get from an AI subscription."
- Jay S.
Join 100,000+ leaders, builders, and innovators

Email address
Already have an account? Sign in
What is included in a subscription?
Daily insights from AI pioneers + early access to powerful AI tools



 Front-row access to the future of AI
Front-row access to the future of AI
 Bundle of AI software
Bundle of AI software

 Dan Shipper
Dan Shipper

.png)

 Evan Armstrong
Evan Armstrong
Comments
Don't have an account? Sign up!
Where is the code you mentioned we will get access to if we subscribe?
@dvainrub+blogs hello, i want to become a member, but couldn't find the tool mentioned here
@hakikiozanerturk coming this week!!
@danshipper very much interested with this tool, please let us know, let me know, publish here or do whatever you can. reeeeally reaaaly interested in it
Hi, where can I get the script? I'm subscribed and can't find it
I'm already a member, and can't find it neither ...
@pudistryalist coming soon!
Instead of using the embedding/search method, where you try to attach relevant data to the prompt, openAI also allows you to directly train a version of GPT on your own data, which is likely to be much more effective!
@beppeben2030 will do coming soon!
@beppeben2030 by training on your own data are you referring to ‘fine tuned’ models? These models are more about appropriate formatting of output rather than adding knowledge to the model. Embedding seems to be the appropriate approach unless training a model from scratch.
Super excited to get my hands on this code! What a brilliant project. My head is spinning with ideas :)
Is this live? Just subscribed :)
Dan - any update on the tool/codebase? curious about the underworkings